How to Streamline Data Pipelines in Databricks with dbx
Robert YousifA step-by-step tutorial: Combining Notebooks, Python Scripts, CICD and Workflows for Scalable Production-Ready data pipelines.
Part 1:
This is the FIRST article in a series of two articles. In this article we will go through:
- Why and when we need to use dbx.
- How a dbx project is structured.
- How to setup, deploy and run a dbx project including:
- Notebooks
- Python scripts
- Workflow Definitions
- Interactive workflow task runs through your IDE
In the SECOND article of the series, we will look into:
- How to instantiate spark and run tests on your local machine
- How to run integration tests in an interactive way using the remote databricks clusters.
- How to connect notebooks to a remote git repository.
- How to apply CI/CD using GitHub actions to test and push your code to a production environment.
- Monitoring the workflows.
- Unity Catalog.
Content
- Introduction
- dbx
- Workflows
- Development patterns with dbx
- Using notebooks - Hands-on — A simple example
- Setup the environment
- Deploying the project
- Integrating the Notebook
- Executing the workflow
- Executing a single Task - Conclusion
Introduction
When it comes to data processing, Databricks has emerged as a leading cloud-based platform that offers a unified environment for data engineering, machine learning, and analytics. However, creating efficient data pipelines can still be challenging, especially when dealing with multiple programming languages, CI/CD integration and reproducible configurations & artifacts. In this article, we delve into the ways in which Databricks CLI eXtension (dbx) can be used to streamline data pipelines in Databricks, providing a step-by-step guide to combining notebooks, Python scripts, and workflows to create reproducible, consistent & scalable production-ready solutions.
When working to establish a production-ready environment, some common questions that arise include:
- Interoperability: How do we create a development life cycle that supports multiple developers working on the same project on different environments?
- Automation: How do we create and manage resources i.e. Clusters, Workflows, Schedules?
- Integration: How do we integrate with other tools i.e. CI/CD?
- Consistency: How do we manage resources in a uniform and standardized way?
- Reproducibility: How do we ensure reproducible results?
In this article we will explore how dbx can simplify the orchestration of complex data pipelines and provide a more efficient and manageable approach to processing large-scale datasets with a step-by-step hands-one example.
dbx
dbx is a command-line interface tool for automating tasks and managing resources in the Databricks platform. It allows users to programmatically interact with Databricks workspaces, workflows, clusters, and other resources, streamlining development and maintenance processes. With dbx, users can automate tasks, integrate Databricks into existing CI/CD pipelines, and manage resources more efficiently.
The benefits of using dbx in Databricks are:
- Interoperability: dbx supports a seamless integration between notebook and python scripts, combining the interactive and exploratory capabilities of notebook with the power and flexibility of python scripts.
- Automation: dbx automates common tasks, such as creating and managing workflows, clusters and schedules, which reduces manual effort and improves efficiency.
- Integration: dbx can be integrated into existing CI/CD pipelines, allowing for a seamless and streamlined development and deployment process.
- Consistency: dbx enables standardized and uniform structure ensuring that all dbx projects and its artifacts are created and managed in a consistent manner.
- Reproducibility: dbx generates artifacts per deployment basis enabling recreation of results based on all previous dbx deployments.
Overall, the use of dbx results in a more streamlined and efficient development and deployment process.
Workflows
Databricks Workflows is fully-managed orchestration service a feature within the Databricks platform that allows users to orchestrate and automate end-to-end data processing and machine learning workflows. Databricks provides a GUI for defining, visualizing and managing complex workflows made up of multiple tasks, allowing users to build and run data pipelines that process and analyze large amounts of data. Workflows can be scheduled to run automatically at specified intervals, or they can be triggered by external events.
Databricks Workflows enables orchestration between a variety of data processing and machine learning tasks, such as data ingestion, data transformation, data preparation, data analysis, model training and deployment. Databricks workflows enables orchestration between the following task types;
- Notebooks
- Python script
- Python wheel
- SQL queries
- Delta Live Table pipeline
- dbt projects
- JAR
- Spark submit
An illustration of such a workflow can be seen in the figure below.
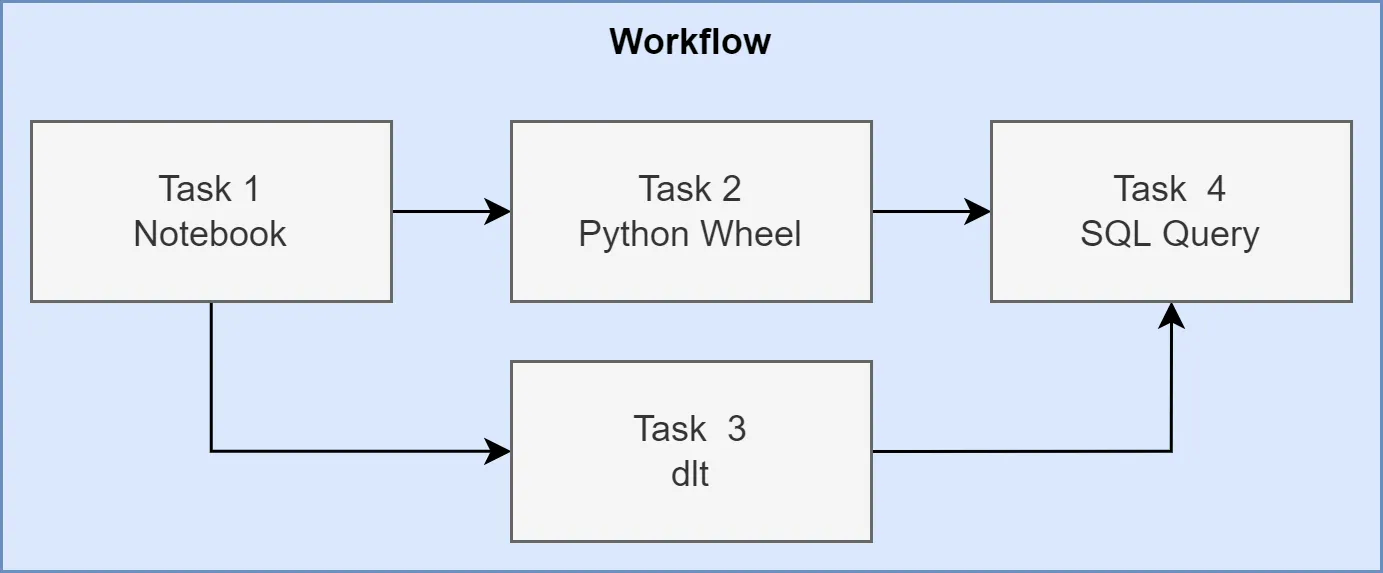
Tasks can depend on each other and also run in tandem. Running tasks in parallel helps distribute the workload and use the full potential of a spark cluster.
In this article, a similar workflow like the one above will be defined programmatically and deployed using the dbx tool (Including task types: Python Wheel and Notebook).
Development patterns using dbx cli
One of the main benefits using dbx is the ability to apply software engineering principals for continuous and agile development illustrated in the following diagram:

- Locally develop your logic and workflow definition.
- Unit & Integration test your logic locally.
- Test your logic on remote development environment
- Run integration tests on remote cluster before deploying dbx project artifacts. - Build (if necessary) and deploy your dbx artifacts to the remote databricks environment.
- Test your whole workflow
Local Development: Developing on your local machine, using your favorite IDE.
These steps are for local development. However, some developers might want to work with databricks notebooks directly in the GUI instead of writing python scripts.
Using Notebooks
Using Databricks notebooks directly in the GUI changes the development pattern and all the code is now developed remotely on the databricks workspace as follows:
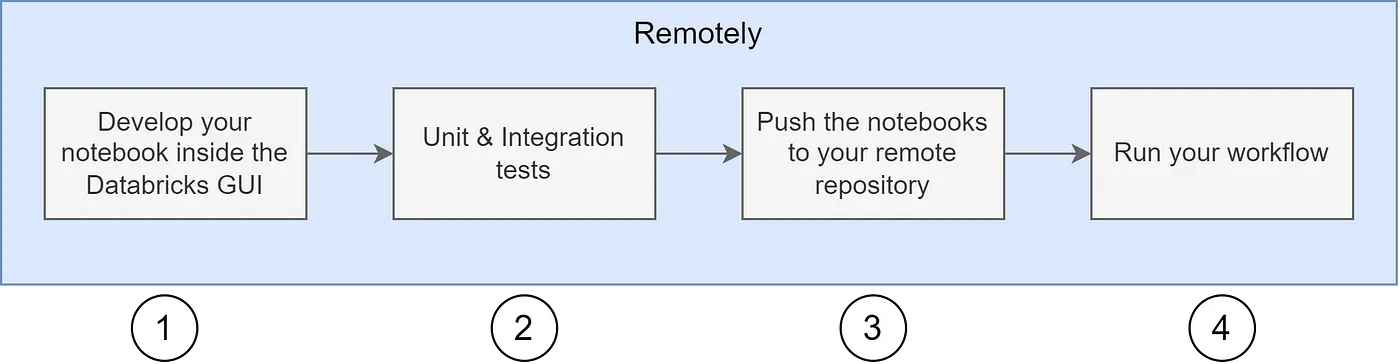
- Develop your logic inside the Databricks GUI.
- Unit and integration test your notebooks.
- Push the notebooks to your git repository (Optional)
- Run your workflow
Now how do we combine both python scripts and notebooks inside the same repository to enable a seamless development environment for multiple users: Using dbx.
A simple example — Hands On
The workflow section of this article has demonstrated the capability of merging various tasks into a single workflow. We have analyzed the conceptual development processes of local development and notebooks. The next step is to address how to effectively integrate these processes in a manner that enables versioning, testing, and deployment of the code base as unified artifacts.
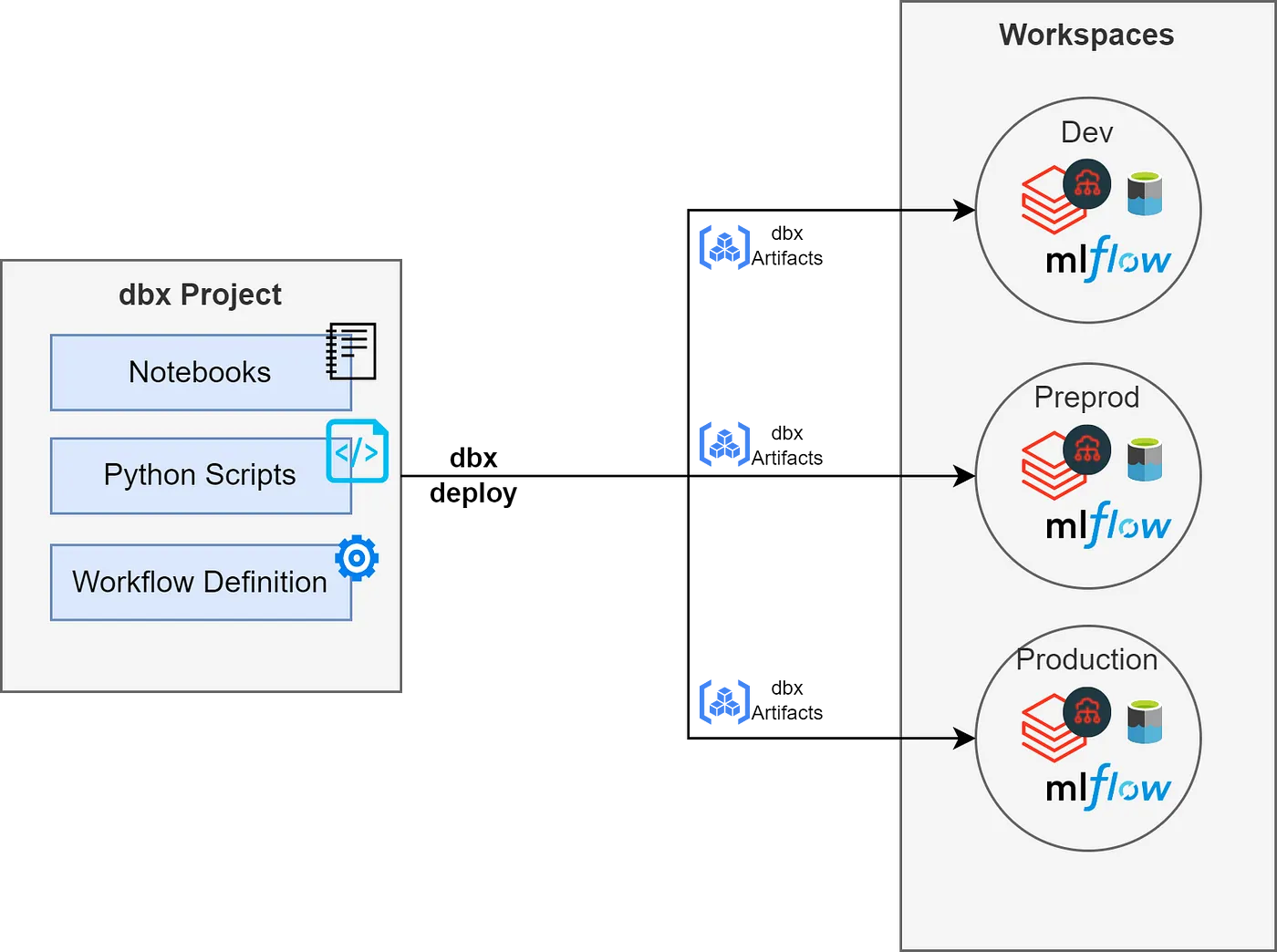
In a setup including Python files and notebooks, a conceptual overview of dbx deployment would look like this:
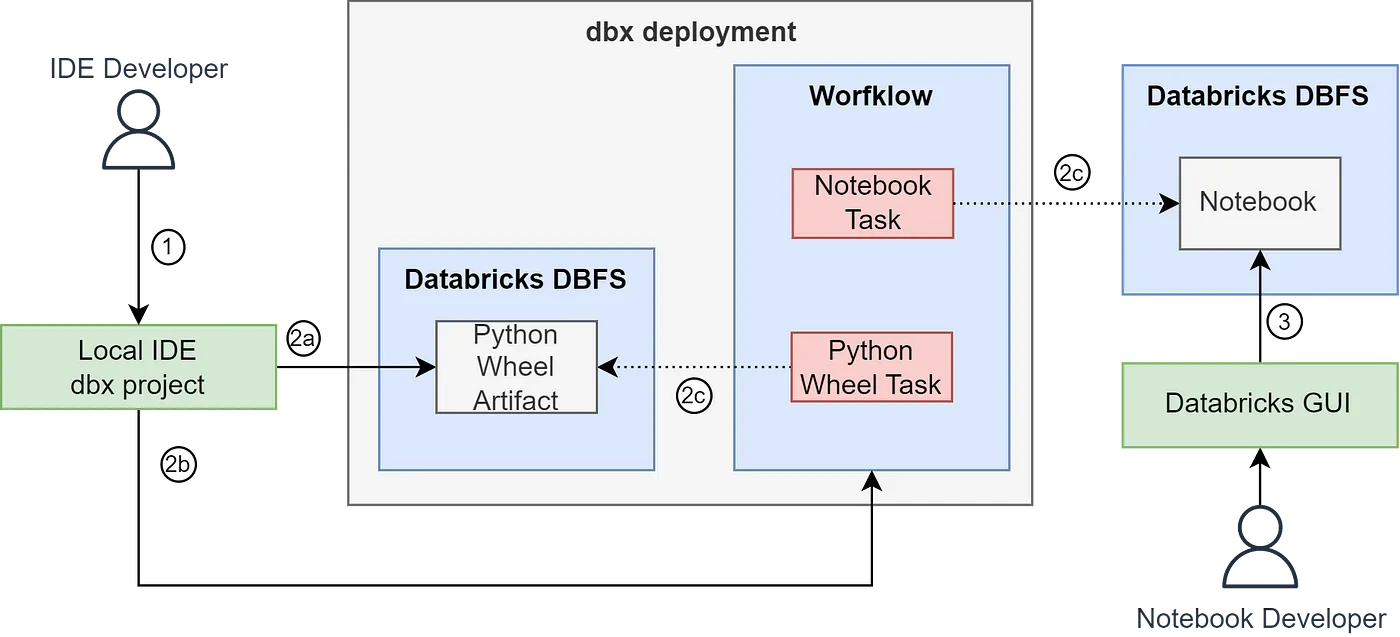
- An IDE developer creates a dbx project, writes the logic and defines the workflow.
- Deployment of the dbx project artifacts.
2a. Python scripts are built as a Python Wheel Artifact and pushed to DBFS (Databricks File System).
2b. The workflow definition is automatically applied through API:s. These definitions contains the tasks that are pointing to their respective artifact in DBFS. (These definitions are also stored as artifacts within DBFS).
2c. The dotted arrows are pointers from the tasks to the logic that will be executed. - The Notebook Developer develops the notebook in the GUI and stores it where the pointer (2c) is pointing.
- The notebook itself is not part of the dbx deployment, only the notebook task of the workflow.
The Notebook task can either point to a notebook inside DBFS or directly to a git repository which we will go through in the second part of this series. This will come in handy when you want to use notebooks in production.
Now lets move to the Hands On part where we will go through these steps to create our own dbx service.
The numbers in the next sections represent the arrows in the illustration above.
Prerequisites:
- Databricks Instance on any cloud provider
- Python with pip (& PySpark for local testing) installed on your local machine
- Basic Python knowledge
1. Setup the environment
- Lets start with cloning the project to your own environment.
git clone https://github.com/robertoooo/dbx_cli_tutorial.git
2. Setup your own python environment and install the requirements based on the setup.py file
python -m venv venv
soruce venv/bin/activate
pip install -e .[local]
# -e will install the packages in editable mode
# .[local] will install the dependencies in both PACKAGE_REQUIRES and LOCAL_REQUIREMENTS.
# This is equivalent of using a requirements.txt file, but this way it is easier to manage the libraries for different environments.
Note: The setup file is responsible for packaging your python wheel, please refer to the code or the dbx documentation for a detailed explanation.
3. Setup the databricks cli connection: Open your Databricks workspace and create a PAT token: User Settings →Access tokens → Generate new token
Use this token to configure your local connection to your own Databricks workspace:
databricks configure --token
# Databricks Host: https://adb-xxxxxxxxxxxxx.x.azuredatabricks.net/
# Token: The token you just generated in the previous step
You can also change or add the token to the .databrickscfg configuration file located in you home directory ( ~/.databrickscfg):
[DEFAULT]
host = https://adb-xxxxxxxxxxxxxxx.xx.azuredatabricks.net/
token = xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
jobs-api-version = 2.1
4. Test the connection with listing your root directory in DBFS:
databricks fs ls
2. Deploying the project
The deployment of your dbx project is represented by the arrows 2a, 2b & 2c in the dbx illustration.
Before we deploy the project, lets have a look at the conf/deployment.yml file. This file contains the workflow definition and will create the python wheel and notebook tasks visualized in the dbx illustration above.
- name: The name of our job
- job_clusters: Cluster definitions
- tasks: The tasks that will be part of your workflow.
- task_key: The name of the task.
- python_wheel_task:Defines a task that will execute a python wheel file, here the package_name and the entry_point of the wheel file is defined. dbx will automatically build and deploy your artifact when running<em>dbx deploy</em>
- notebook_task:Defines a task that will execute a notebook, the source of the notebook can be either workspace or git provider. - depends_on: The task(s) to depend on.
This workflow definition will create two tasks:
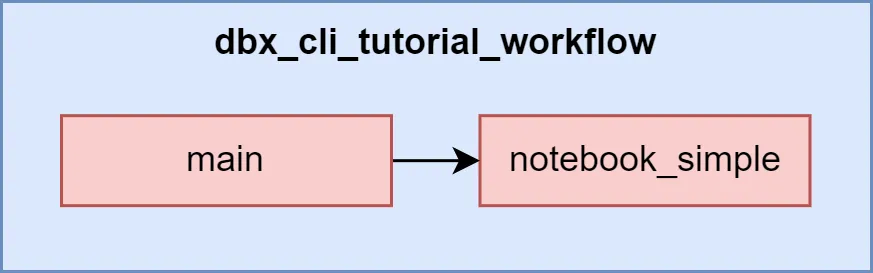
- main: A Python wheel task, that will run the entry point
etl_jobof the package nameworkloads
- Theetl_jobentry point is defined in thesetup.pyfile. - notebook_simple: A notebook task that will run the notebook defined in the
notebook_path. In this example the notebook is part of the dbx project which we will add to databricks repos in step 3.
To deploy the project to your workspace, you only need to run the following command:
dbx deploy
The following steps are being executed:
- The dbx client reads the workflow definition YAML file, which specifies the order and dependencies of the tasks in the workflow.
- The dbx client validates the workflow definition to ensure that it is well-formed and contains all the necessary information.
- The dbx client determines which artifacts need to be built and uploaded to the Databricks File System (DBFS) and begins building them if necessary. This includes building Python wheel files and generating the workflow deployment results.
- The dbx client uploads the artifacts to DBFS.
- The dbx client creates the workflow.
- Once all tasks have completed successfully, the dbx client reports that the workflow has been deployed and is ready for execution.
Now that we have deployed our project, the following is created inside the databricks workspace:
- The workflow with the name
dbx_cli_tutorial_job - An mlflow experiment used to track all your deployments and artifacts
- The artifact in the form of a wheel file stored in dbfs.
Go to your workspace and check the following:
- Workflows — Select the
dbx_cli_tutorial_workflowand check out theTaskstab to see your tasks. - Experiments (You have to select the Machine Learning environment)
- Select the<em>dbx_cli_tutorial</em>experiment and your run.
- Look at the artifacts created and where they are stored. To change the location, please check the documentation.
3. Integrating the Notebook
The notebook itself is not part of the dbx deployment, as it is only referenced by the workflow definition. Therefore for our workflow to succeed we need to add the git dbx project and store it where the notebook task is pointing (The path of the notebook task).
- task_key: "notebook_simple"
job_cluster_key: "default"
notebook_task:
notebook_path: "/Repos/dbx_projects/dbx_cli_tutorial/notebooks/simple_notebook_task"
source: WORKSPACE
Go to your databricks workspace and do the following:
- Click on
Repos -> Add folderwith the namedbx_projects. - Choose the newly created folder and
Add Repowith the github url andCreate Repo.
- Make sure that theRepository nameisdbx_cli_tutorial
https://github.com/robertoooo/dbx_cli_tutorial.git
This github repository is the same used throughout the project containing the dbx project. If you want to store your notebook somewhere else, you can change the notebook_path inside the deployment.yml file. It is also possible to reference a notebook inside a git repository directly.
Now that we have deployed the project, created our notebook, the next step is to run the workflow.
Executing the workflow
Before running the workflow, lets look into what the tasks actually does.
The main task reads a sample dataset called nyctaxi-with-zipcodes
and stages it in the hive metastore as a delta table with the name bronze_nytaxi. Furthermore, the same dataframe stored is augmented with a new column called duration_seconds and then stored in a another delta table called silver_taxi.
Unity Catalog: The table can also be saved using the Unity Catalog if your workspace is part of a metastore.
We are using the static methods of the class Utils to read and write the tables. The reason for this is to simplify writing tests for the methods utilizing test driven development. We will look closer into test driven development and integration test in the next part of this article.
The Utils class looks like the following:
The second task named notebook_simple runs the simple_notebook_task where we aggregate the silver_nytaxi table.
The easiest way to run the workflow is by clicking on the Run now button inside your workflows.
Another way to run your workflow is to do it programmatically as follows:
dbx launch --job dbx_cli_tutorial_workflow
Maybe you realize that the run takes a few minutes, even though the transformations are not computationally heavy, the reason for this is that job_clusters is defined in the deployment.yml configuration. This will create a new job cluster every time the workflow runs and turn it off as soon as the workflow is done. This is recommended for production workloads, however if you want to run it a bit faster for debugging & development you can swap to an interactive cluster before running your workflow.
This change will be overwritten every time you deploy your project with dbx_deply by the definition in your deployment.yml configuration. Changing the configuration in the deployment file to an interactive cluster is also possible, but you have to be careful not to push these settings to production. To overcome running the whole workflow every time you want to test one single task, you can use dbx execute which will be demonstrated next.
Executing a single Task (Part of your workflow)
Now you might want to run just one single task of your workflow against your interactive cluster, this can easily be done with the following command:
dbx execute --cluster-name "interactive-cluster-name" --job "dbx_cli_tutorial_workflow" --task "main"
Here cluster-name needs to be replaced with your own interactive cluster. This will:
- Build the project
- Push the build to the remote workspace as temporary files
- Install the library on your cluster (Session scoped)
- Run the task
This will also return the STDOUT & STDERR directly to your terminal where your run the command.
Now there is even a lighter way to do this where you will run your code directly without having to build the code. This option is however in public preview and only support by VSCode.
Conclusion
The challenges of developing and overseeing workflow pipelines in complex environments with varying end-user preferences can be addressed through the use of dbx. By addressing common questions around interoperability, automation, integration, consistency, and reproducibility, dbx provides a framework for managing resources, creating and overseeing workflows, and ensuring reproducible results. With the help of dbx, organizations can establish a production-ready environment that supports multiple users working on the same project on different environments.
In the second part of this article, we will dive deeper into the practical aspects of using dbx to streamline your development process. We will explore how to instantiate Spark and run tests on your local machine, as well as how to run integration tests in an interactive way using remote Databricks clusters. We will also cover how to connect your notebooks to a remote git repository, and how to apply CI/CD using GitHub actions to test and push your code to a production environment. By the end of this series, you will have a solid understanding of how to use dbx to create production ready data pipelines.